
Last updated on 23rd Jun 2026| 4456
- Introduction to Machine Learning and Its Importance
- Understanding Types of Machine Learning
- Essential Mathematics for Machine Learning
- Data Collection and Data Preprocessing Techniques
- Exploratory Data Analysis for Machine Learning Projects
- Popular Machine Learning Algorithms for Beginners
- Model Training and Evaluation Methods
- Tools and Libraries Used in Machine Learning
- Common Challenges Faced by Data Science Interns
- Conclusion: Building a Strong Foundation in Machine Learning
Introduction to Machine Learning and Its Importance
Machine learning is a branch of artificial intelligence that enables computers to learn from data and make predictions or decisions without being explicitly programmed for every task. It has become one of the most important technologies in modern industries, powering applications such as recommendation systems, fraud detection, image recognition, chatbots, and predictive analytics. For data science interns, understanding machine learning is essential because it forms the foundation of many data-driven solutions used by organizations worldwide and Data Science Training. Machine learning helps businesses analyze large volumes of data, identify patterns, and generate actionable insights that improve decision-making and operational efficiency. As industries increasingly adopt AI-powered technologies, the demand for professionals with machine learning skills continues to grow. Learning the fundamentals of machine learning allows interns to work on real-world projects, develop analytical thinking, and build a strong foundation for careers in data science, artificial intelligence, and advanced analytics.
Understanding Types of Machine Learning
Machine learning is generally divided into three major categories: supervised learning, unsupervised learning, and reinforcement learning. Supervised learning involves training models using labeled datasets where the correct output is already known. Common applications include classification and regression tasks such as spam detection and sales forecasting then Learn more in Data Science Training. Unsupervised learning works with unlabeled data and focuses on discovering hidden patterns, relationships, or clusters within datasets. Techniques such as clustering and dimensionality reduction fall into this category. Reinforcement learning is based on an agent learning through trial and error by interacting with an environment and receiving rewards or penalties for its actions. Each type serves different business needs and problem-solving scenarios. Understanding these categories helps data science interns identify the most suitable approach for specific projects and develop a broader understanding of machine learning applications across industries.
Get Your Data Science Certification by Learning from Industry-Leading Experts and Advancing Your Career with ACTE’s Gen AI Course.
Data Collection and Data Preprocessing Techniques
Data collection and preprocessing are critical steps in any machine learning project because model performance largely depends on data quality. Data can be collected from databases, websites, APIs, sensors, surveys, or business applications. Once collected, the data often contains missing values, inconsistencies, duplicate records, and irrelevant information that must be cleaned before analysis. Preprocessing techniques include handling missing values, removing duplicates, normalizing data, encoding categorical variables, and scaling numerical features. Feature engineering is another important step where new variables are created to improve model performance and learn Spark SQL Tutorial. Data science interns must learn these techniques because poorly prepared data can lead to inaccurate predictions and unreliable results. Effective preprocessing ensures that machine learning algorithms receive clean, structured, and meaningful data, increasing the chances of building accurate and efficient predictive models.
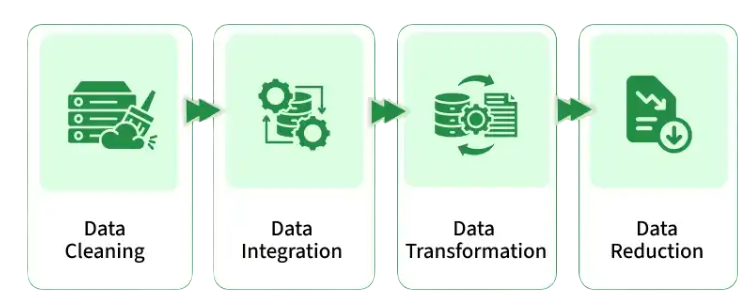
Exploratory Data Analysis for Machine Learning Projects
Exploratory Data Analysis (EDA) is the process of examining datasets to understand their structure, patterns, and relationships before applying machine learning algorithms. EDA helps identify trends, outliers, missing values, and correlations that may affect model performance. Data scientists use statistical summaries and visualization techniques such as histograms, scatter plots, box plots, and heatmaps to gain insights into the data. This step is essential because it helps determine which features are important and what preprocessing techniques may be required and Marketing Internships Explained. For data science interns, EDA provides a deeper understanding of the dataset and improves decision-making throughout the machine learning workflow. Proper exploratory analysis can reveal hidden opportunities, reduce errors, and increase model accuracy by ensuring that the data is thoroughly understood before model development begins.

Popular Machine Learning Algorithms for Beginners
Beginners in machine learning are often introduced to algorithms that are easy to understand and widely used in industry projects. Linear Regression is commonly used for predicting continuous values such as sales or revenue. Logistic Regression helps solve classification problems by predicting categories. Decision Trees provide a visual and interpretable approach to decision-making based on data conditions. K-Nearest Neighbors (KNN) classifies data points based on similarities with nearby observations and HR Internship Duties and Skills . Naive Bayes is a probabilistic algorithm frequently used in text classification tasks such as spam filtering. Random Forest combines multiple decision trees to improve prediction accuracy and reduce overfitting. These algorithms help interns understand fundamental machine learning concepts while gaining practical experience in solving real-world problems. Learning these techniques builds a strong foundation for exploring more advanced machine learning methods.

Get JOB Oriented Data Science Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Model Training and Evaluation Methods
Model training involves teaching a machine learning algorithm to identify patterns within a dataset and make predictions based on learned relationships. During training, data is typically divided into training and testing sets to evaluate how well the model performs on unseen information and How to get a data science internship as a fresher . Evaluation metrics vary depending on the problem type. For classification tasks, metrics such as accuracy, precision, recall, and F1-score are commonly used. For regression problems, Mean Absolute Error (MAE), Mean Squared Error (MSE), and R-squared values help assess performance. Cross-validation techniques further improve reliability by testing models across multiple data subsets. Data science interns should understand model evaluation because selecting the right metrics is essential for measuring success and identifying areas for improvement. Proper evaluation ensures that machine learning models deliver reliable and accurate predictions in real-world applications.
Want to Master Data Science? Explore the Data Science Master Program Offered at ACTE Today!
Tools and Libraries Used in Machine Learning
Machine learning projects rely on a wide range of tools and libraries that simplify data analysis, model development, evaluation, and deployment. Python has become the most popular programming language for machine learning because of its simplicity, readability, and extensive ecosystem of libraries. Core libraries such as NumPy support numerical computations, while Pandas provides powerful data manipulation and analysis capabilities and Data Science Interview Preparation . Data visualization libraries such as Matplotlib and Seaborn help professionals understand trends, patterns, and relationships within datasets through charts and graphs. Scikit-learn is one of the most widely used machine learning libraries, offering a variety of algorithms for classification, regression, clustering, and model evaluation.
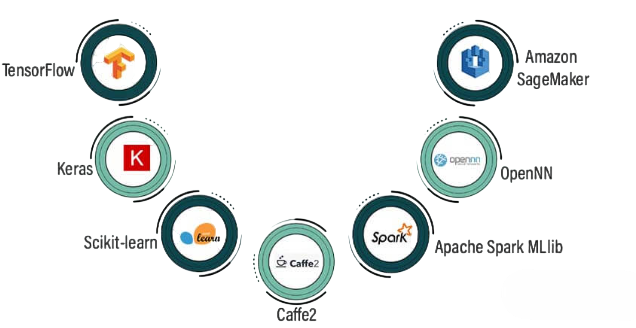
For deep learning projects, TensorFlow and PyTorch provide advanced frameworks for building neural networks and artificial intelligence applications. Jupyter Notebook enables interactive coding, experimentation, and documentation, making it a favorite tool among data scientists and researchers. Version control platforms such as Git and GitHub facilitate collaboration, code management, and project tracking across teams. In addition, cloud platforms like AWS, Microsoft Azure, and Google Cloud provide scalable infrastructure for training and deploying machine learning models on large datasets.
Want to Learn About DevOps? Explore Our Data Science Interview Questions and Answers Featuring the Most Frequently Asked Questions in Job Interviews.
Common Challenges Faced by Data Science Interns
Data science interns frequently encounter challenges while learning and implementing machine learning concepts in practical environments. One of the biggest obstacles is dealing with raw, incomplete, and inconsistent datasets that require extensive cleaning and preprocessing before meaningful analysis can begin. Missing values, duplicate records, and incorrect data formats often create difficulties that beginners may not be prepared to handle and Data Science Training. Another common challenge is understanding the mathematical foundations behind machine learning algorithms, including statistics, probability, linear algebra, and optimization techniques. Interns may also struggle with selecting the most appropriate algorithm for a specific problem, tuning hyperparameters, and interpreting model performance metrics accurately. Limited access to high-quality datasets, computing resources, and industry-specific business knowledge can further complicate project development. Despite these challenges, internships provide valuable opportunities for growth through mentorship, teamwork, and hands-on experience that strengthen technical and professional capabilities.
Conclusion: Building a Strong Foundation in Machine Learning
Building a strong foundation in machine learning is essential for data science interns who aim to establish successful careers in analytics, artificial intelligence, and data-driven decision-making. Machine learning combines mathematics, programming, statistics, and domain knowledge to transform raw data into meaningful insights and predictive solutions. Understanding the fundamental concepts of supervised learning, unsupervised learning, data preprocessing, exploratory data analysis, model training, and evaluation provides a solid starting point for tackling real-world business problems. Equally important is gaining practical experience through projects, internships, competitions, and collaborative learning opportunities and Data Science Training. Working with industry-standard tools and libraries such as Python, Scikit-learn, TensorFlow, and cloud platforms helps interns develop technical skills that are highly valued by employers. By focusing on both theoretical understanding and practical application, data science interns can create a solid pathway toward becoming skilled machine learning practitioners and future data science professionals.




